
기록하는 공부
[Colab 실습] 프로야구 선수의 다음 해 연봉 예측하기 / Colab 사용법 / csv 파일 불러오기 / 한글 깨짐 오류 / 회귀분석 / 머신러닝 / 데이터 분석 본문
Language/Python
[Colab 실습] 프로야구 선수의 다음 해 연봉 예측하기 / Colab 사용법 / csv 파일 불러오기 / 한글 깨짐 오류 / 회귀분석 / 머신러닝 / 데이터 분석
SS_StudySteadily 2023. 6. 13. 00:11728x90
반응형
1. 구글 로그인을 한 후, 구글 드라이브에 접속한다.

2. 드라이브에 들어온 후 새로 만들기를 누른다.

3. 새로 만들기에서 [더보기] - [Google Colaboratory]를 누른다.
만약, 없다면 연결할 앱 더보기를 눌러 Colaboratory를 검색 후 설치하면 된다.

4. 파일이 하나 생성되고 이제 코드를 작성할 수 있다.

5. 아래와 같이 코드를 입력한다.
# -*- coding: utf-8 -*-
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
6. 데이터 파일을 가져온다. 이대로 코드를 작성한다면 오류가 발생한다.
왜냐하면, 데이터 파일 경로와 구글 드라이브에서 해당 데이터를 가져올 수 있도록 코드를 추가해야 하기 때문이다.
<수정 전>
# Data Source : http://www.statiz.co.kr/
picher_file_path = '../data/picher_stats_2017.csv'
batter_file_path = '../data/batter_stats_2017.csv'
picher = pd.read_csv(picher_file_path)
batter = pd.read_csv(batter_file_path)
<수정 후>
# Data Source : http://www.statiz.co.kr/
from google.colab import drive
drive.mount('/content/data')
picher_file_path = '/content/data/MyDrive/Colab Notebooks/batter_stats_2017.csv'
batter_file_path = '/content/data/MyDrive/Colab Notebooks/picher_stats_2017.csv'
picher = pd.read_csv(picher_file_path)
batter = pd.read_csv(batter_file_path)
소스 코드 실행 전, 불러올 데이터 파일과 소스 파일에 경로가 같아야 한다.
필자는 내 드라이브 > Colab Notebooks에 사용할 데이터 파일을 미리 옮겨 놓았다.

다시 소스 코드 파일로 넘어와서 오른쪽 파일을 누르면 data 폴더 하위에 데이터 파일이 있는 경로를 확인할 수 있다.
데이터 파일의 경로를 알기 위해 파일명에서 우클릭을 한 후 경로복사를 클릭하여 소스 코드 파일 경로에 붙여넣기 한다.

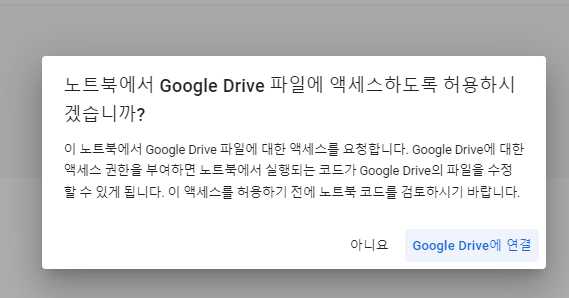
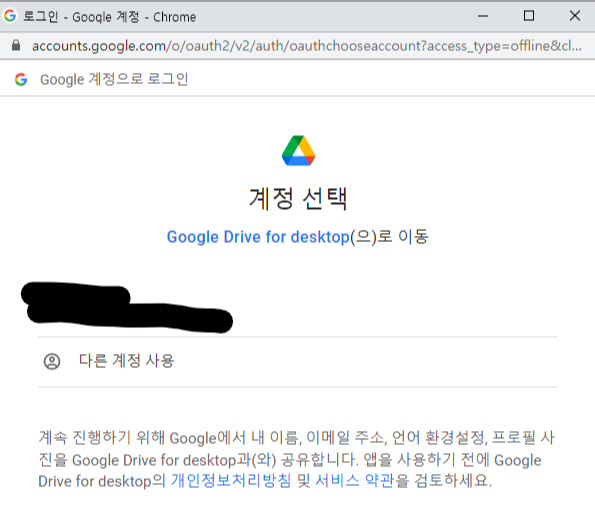
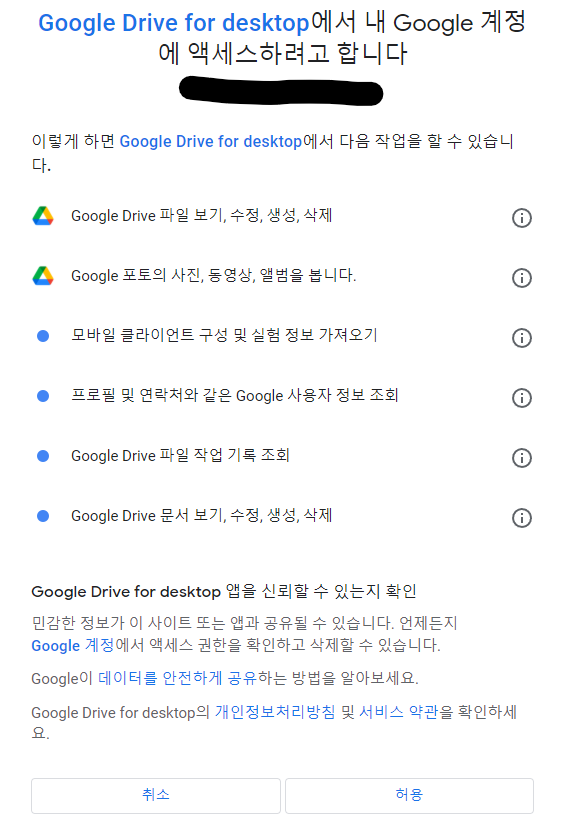
7. 6번에서 코드를 추가하면 아래와 같은 알림창이 뜨고 액세스를 허용하면 된다.
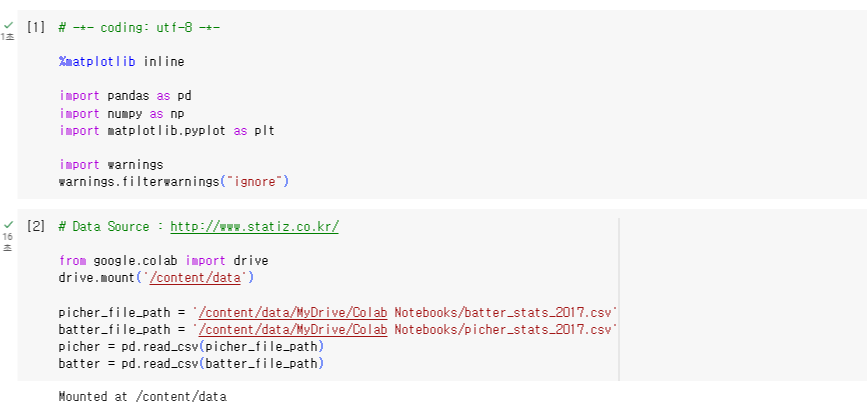
8. 여기까지 실행 코드 결과이다.
<Step1. 탐색> 프로야구 연봉 데이터 살펴보기
1. picher.columns을 사용해 칼럼을 확인해보자.

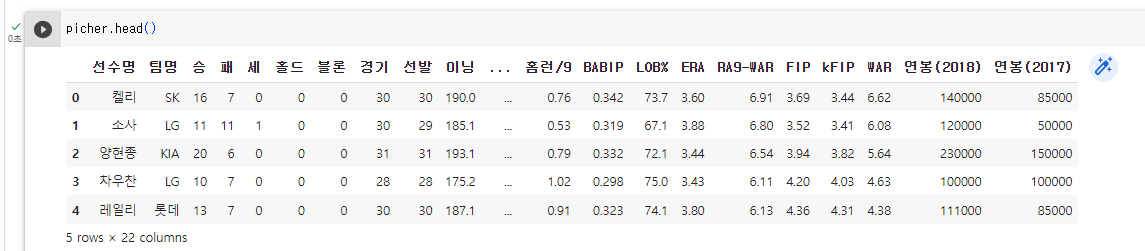
2. picher.head()를 사용해 데이터 전체 중 상위에 있는 데이터를 확인해 보자.
5개의 행과 22개의 열이 있는 것을 확인할 수 있다.
3. print(picher.shape) 확인해 보자.
총 152행 22열이 있는 것을 확인할 수 있다.

한글 깨짐 오류 현상 해결
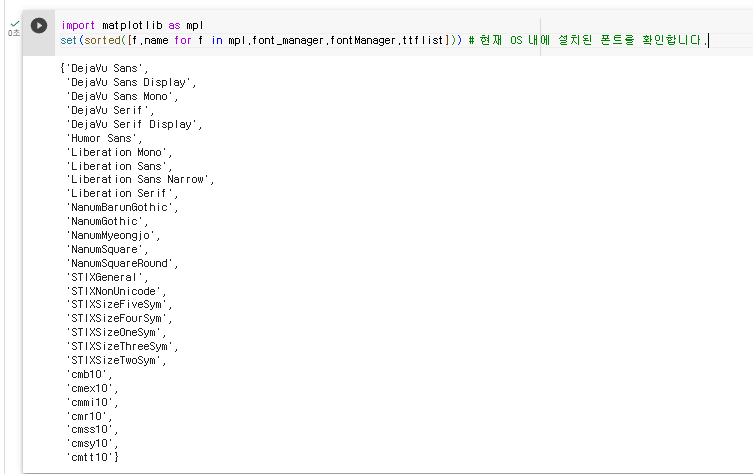
1. 아래 코드를 입력하여 현재 os 내에 설치된 폰트를 확인한다.
import matplotlib as mpl
set(sorted([f.name for f in mpl.font_manager.fontManager.ttflist]))
2. 한글 글꼴이 없다면 설치한다.
이 명령어를 사용해 나눔 글꼴을 설치하고 런타임 다시 시작을 누른다.
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf

5. 자신의 OS에 존재하는 한글 폰트를 선택한다.
필자는 방금 설치한 나눔 고딕체를 선택했다.
mpl.rc('font', family='NanumGothic')
예측할 대상인 '연봉'에 대한 정보 확인하기
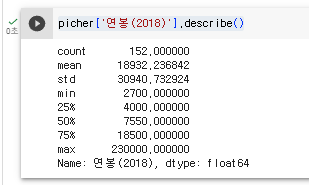
1. 연봉에 대한 정보를 파악하기 위해 아래 코드를 실행시켜 본다.
picher['연봉(2018)'].describe()
2. 2018년 연봉 분포를 출력한다.
picher['연봉(2018)'].hist(bins=100) # 2018년 연봉 분포를 출력합니다.
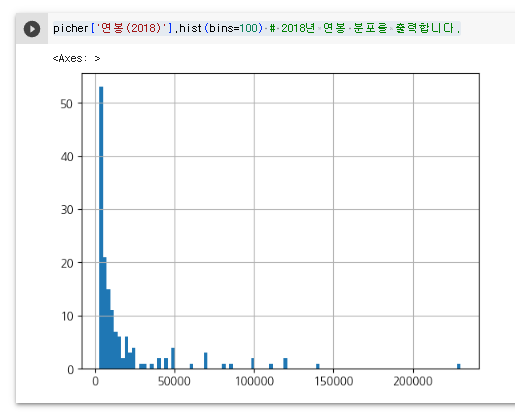
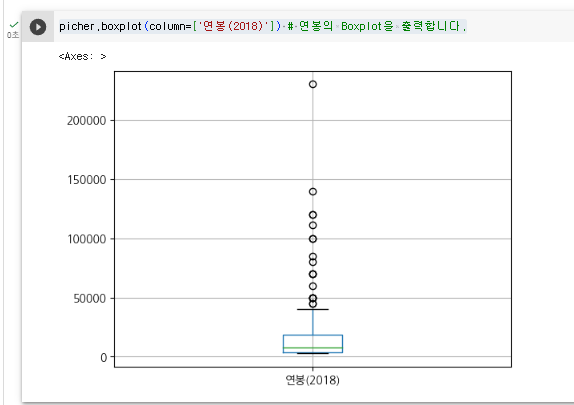
3. 연봉의 Boxplot을 출력해 본다.
picher.boxplot(column=['연봉(2018)']) # 연봉의 Boxplot을 출력합니다.
회귀 분석에 사용할 피처 살펴보기
1. 피쳐 각각의 대한 히스토그램을 출력하고 df의 column 개수만큼 subplot을 출력한다.
picher_features_df = picher[['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR',
'연봉(2018)', '연봉(2017)']]# 피처 각각에 대한 histogram을 출력합니다.
def plot_hist_each_column(df):
plt.rcParams['figure.figsize'] = [20, 16]
fig = plt.figure(1)
# df의 column 갯수 만큼의 subplot을 출력합니다.
for i in range(len(df.columns)):
ax = fig.add_subplot(5, 5, i+1)
plt.hist(df[df.columns[i]], bins=50)
ax.set_title(df.columns[i])
plt.show()plot_hist_each_column(picher_features_df)
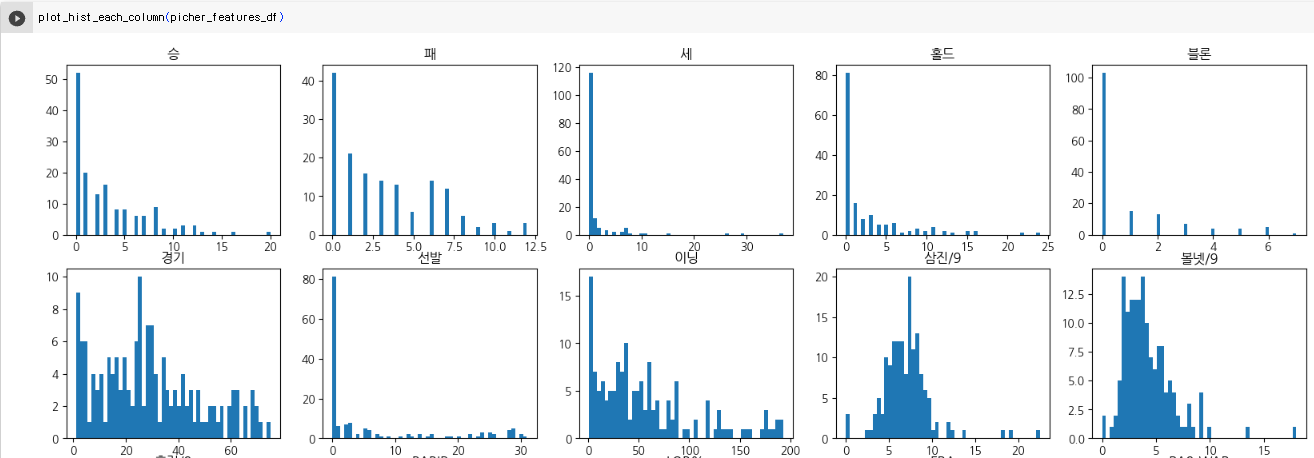
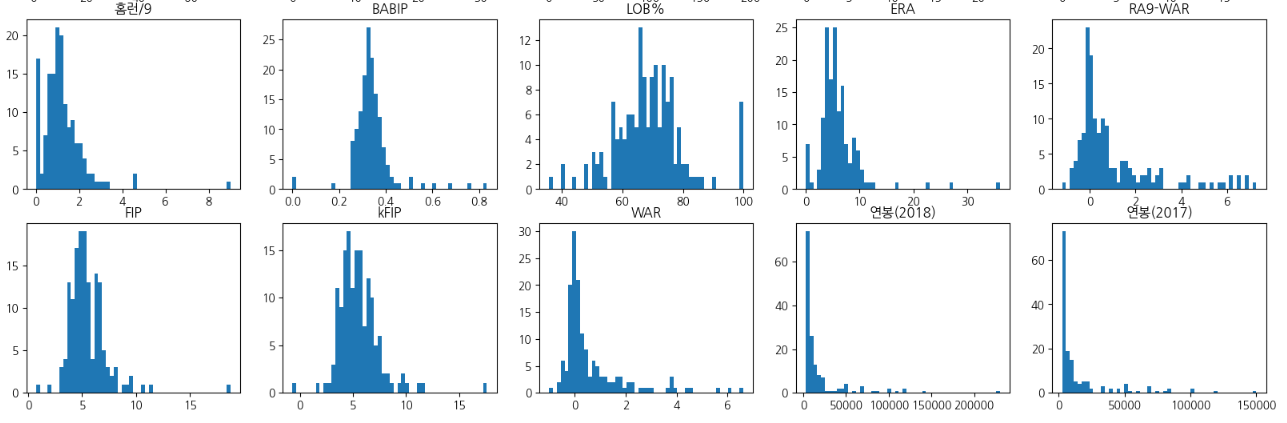
<Step2. 예측> : 투수의 연봉 예측하기
1. 피처들의 단위를 맞춰주기 위해서 피처 스케일링을 진행한다.
# pandas 형태로 정의된 데이터를 출력할 때, scientific-notation이 아닌 float 모양으로 출력되게 해줍니다.
pd.options.mode.chained_assignment = None# 피처 각각에 대한 scaling을 수행하는 함수를 정의합니다.
def standard_scaling(df, scale_columns):
for col in scale_columns:
series_mean = df[col].mean()
series_std = df[col].std()
df[col] = df[col].apply(lambda x: (x-series_mean)/series_std)
return df# 피처 각각에 대한 scaling을 수행합니다.
scale_columns = ['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR', '연봉(2017)']
picher_df = standard_scaling(picher, scale_columns)picher_df = picher_df.rename(columns={'연봉(2018)': 'y'})
picher_df.head(5)
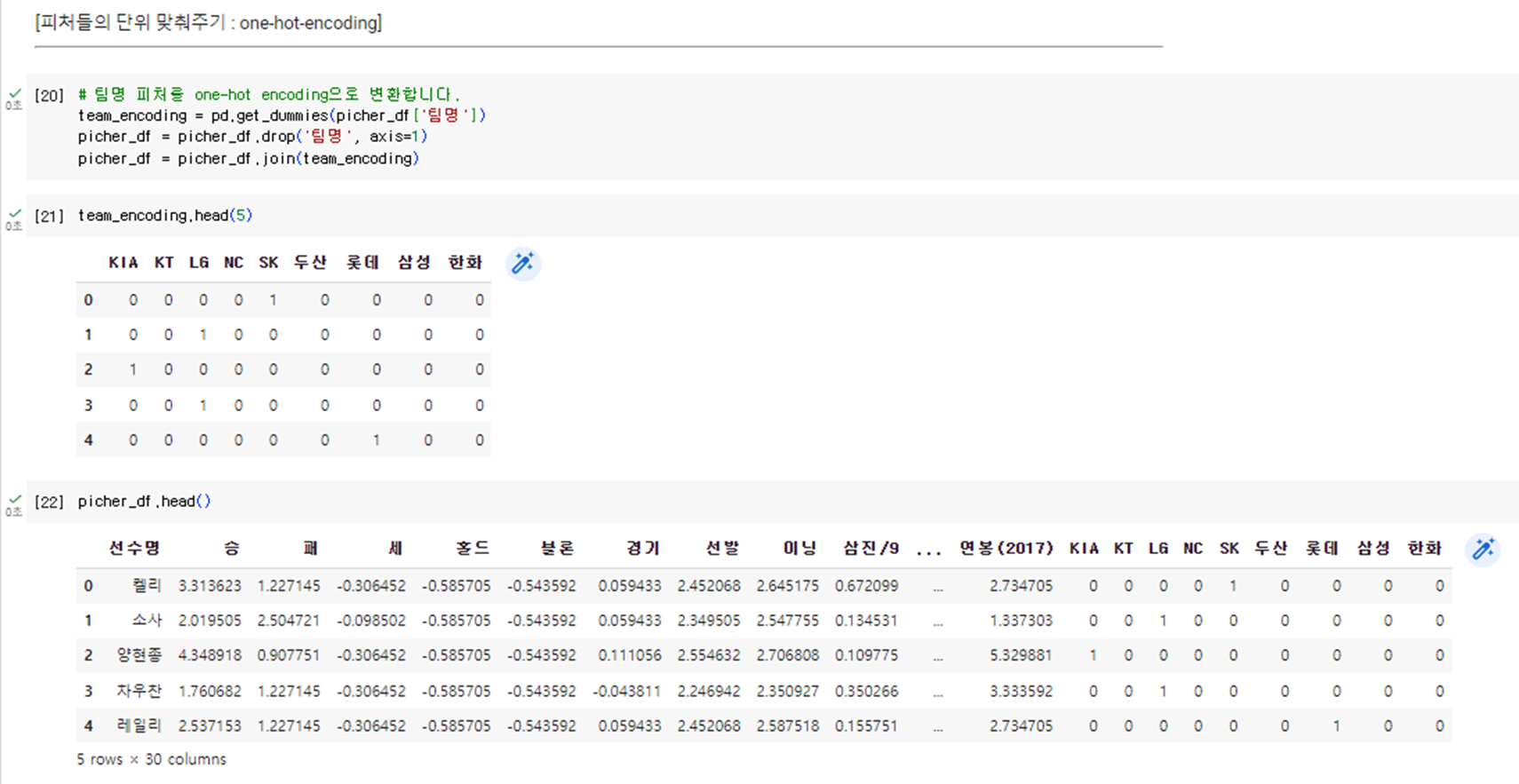
2. 다음에는 피처들의 단위를 맞춰주기 위해 one-hot-encoding을 진행한다.
# 팀명 피처를 one-hot encoding으로 변환합니다.
team_encoding = pd.get_dummies(picher_df['팀명'])
picher_df = picher_df.drop('팀명', axis=1)
picher_df = picher_df.join(team_encoding)team_encoding.head(5)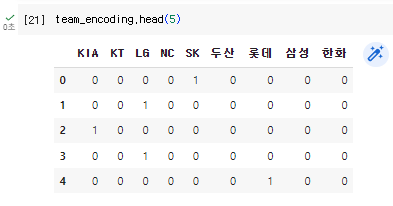
picher_df.head()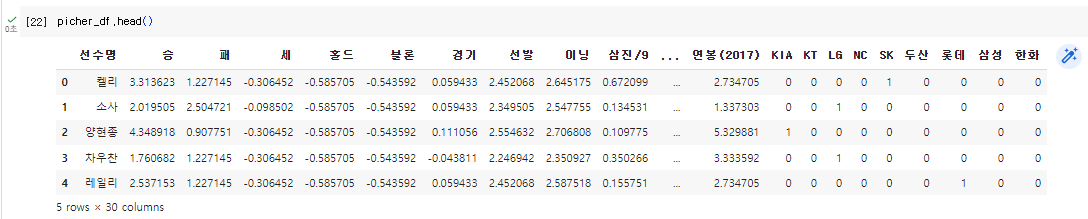
<Step3. 평가> : 예측 모델 평가하기
1. 어떤 피처가 가장 영향력이 강한 피처인지 살펴보자.
!pip install statsmodelsimport statsmodels.api as sm
# statsmodel 라이브러리로 회귀 분석을 수행합니다.
X_train = sm.add_constant(X_train)
model = sm.OLS(y_train, X_train).fit()
model.summary()

2. 회귀 계수를 리스트로 반환한 후 출력한다.
# 한글 출력을 위한 사전 설정 단계입니다.
mpl.rc('font', family='AppleGothic')
plt.rcParams['figure.figsize'] = [20, 16]
# 회귀 계수를 리스트로 반환합니다.
coefs = model.params.tolist()
coefs_series = pd.Series(coefs)
# 변수명을 리스트로 반환합니다.
x_labels = model.params.index.tolist()
# 회귀 계수를 출력합니다.
ax = coefs_series.plot(kind='bar')
ax.set_title('feature_coef_graph')
ax.set_xlabel('x_features')
ax.set_ylabel('coef')
ax.set_xticklabels(x_labels)
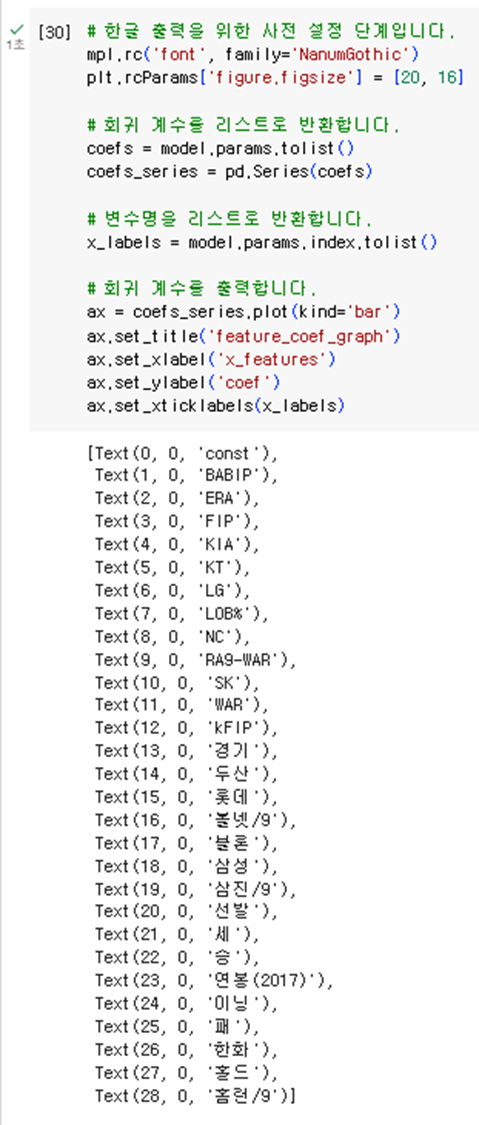
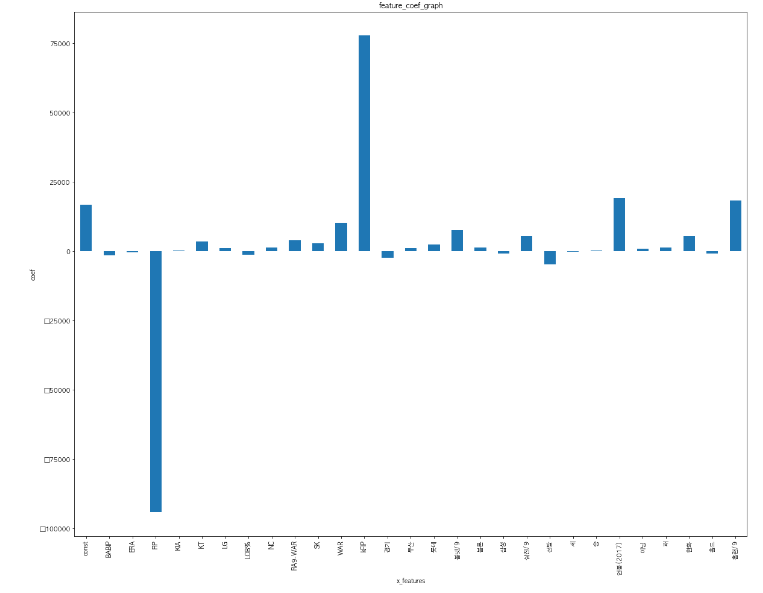
예측 모델의 평가
1. 학습 데이터와 테스트 데이터로 분리하고 회귀 분석 모델을 학습한다.
# 학습 데이터와 테스트 데이터로 분리합니다.
X = picher_df[picher_df.columns.difference(['선수명', 'y'])]
y = picher_df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)# 회귀 분석 모델을 학습합니다.
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
2. R2 score와 RMSE score을 이용해 회귀 분석 모델을 평가한다.
# 회귀 분석 모델을 평가합니다.
print(model.score(X_train, y_train)) # train R2 score를 출력합니다.
print(model.score(X_test, y_test)) # test R2 score를 출력합니다.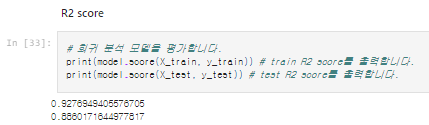
# 회귀 분석 모델을 평가합니다.
y_predictions = lr.predict(X_train)
print(sqrt(mean_squared_error(y_train, y_predictions))) # train RMSE score를 출력합니다.
y_predictions = lr.predict(X_test)
print(sqrt(mean_squared_error(y_test, y_predictions))) # test RMSE score를 출력합니다.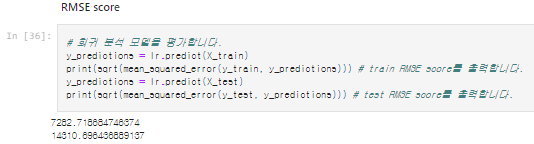
3. 모델 평가를 통해 확인했을 때, train score와 test score의 점수 간의 차이가 큰 것을 확인할 수 있다. 일반적으로 두 값이 차이가 없어야 이상적인 모델이라고 할 수 있다. 이 차이가 클수록 모델이 훈련 데이터 셋에 과적합된 것이므로 이상적인 모델이라 할 수 없다.
피처들의 상관관계 분석
피처 간의 상관계수 행렬을 계산하고 히트맵으로 시각화한다.
import seaborn as sns
# 피처간의 상관계수 행렬을 계산합니다.
corr = picher_df[scale_columns].corr(method='pearson')
show_cols = ['win', 'lose', 'save', 'hold', 'blon', 'match', 'start',
'inning', 'strike3', 'ball4', 'homerun', 'BABIP', 'LOB',
'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR', '2017']
# corr 행렬 히트맵을 시각화합니다.
plt.rc('font', family='NanumGothicOTF')
sns.set(font_scale=1.5)
hm = sns.heatmap(corr.values,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 15},
yticklabels=show_cols,
xticklabels=show_cols)
plt.tight_layout()
plt.show()
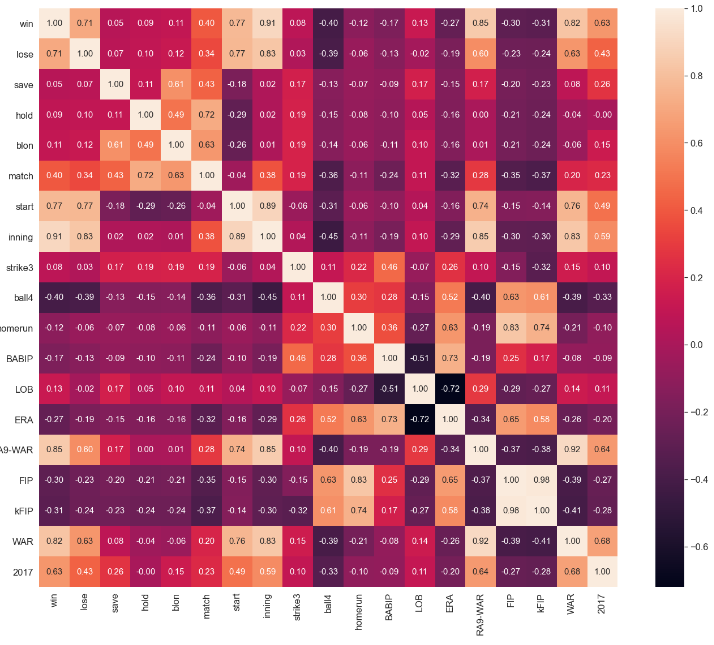
[회귀분석 예측 성능을 높이기 위한 방법 : 다중공선성 확인]
각 피처마다 VIF 계수를 출력한다.
from statsmodels.stats.outliers_influence import variance_inflation_factorvif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
vif.round(1)
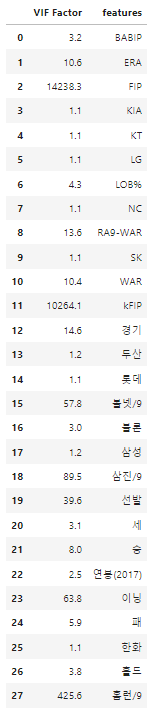
모델을 다시 학습시키기 위해 적절한 피처를 재선정한다.
이때 VIF 계수가 높은 피처들을 우선적으로 제거하고 유사한 두 가지 피처 중에는 하나만을 제거한다.
공선성을 검증하고 여전히 VIF 계수가 높은 피처들은 제거한다.
남은 피처를 토대로 다시 한번 회귀분석을 한다.
적절한 피처로 다시 학습하기
1. 피처를 재선정하고 모델을 학습한 후 결과를 출력한다.
# 피처를 재선정합니다.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
y = picher_df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)# 모델을 학습합니다.
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)# 결과를 출력합니다.
print(model.score(X_train, y_train)) # train R2 score를 출력합니다.
print(model.score(X_test, y_test)) # test R2 score를 출력합니다.

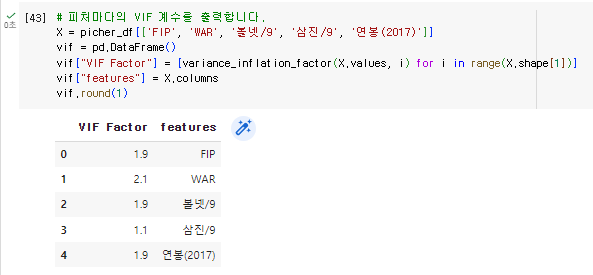
2. 회귀 분석 모델을 평가하고 피처마다의 VIF 계수를 출력한다.
# 회귀 분석 모델을 평가합니다.
y_predictions = lr.predict(X_train)
print(sqrt(mean_squared_error(y_train, y_predictions))) # train RMSE score를 출력합니다.
y_predictions = lr.predict(X_test)
print(sqrt(mean_squared_error(y_test, y_predictions))) # test RMSE score를 출력합니다.

# 피처마다의 VIF 계수를 출력합니다.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
vif.round(1)
<Step4. 시각화> : 분석 결과의 시각화
이제 완성된 모델을 가지고 예상 연봉과 실제 연봉 비교해 보자.
# 2018년 연봉을 예측하여 데이터프레임의 column으로 생성합니다.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
predict_2018_salary = lr.predict(X)
picher_df['예측연봉(2018)'] = pd.Series(predict_2018_salary)
# 원래의 데이터 프레임을 다시 로드합니다.
picher = pd.read_csv(picher_file_path)
picher = picher[['선수명', '연봉(2017)']]
# 원래의 데이터 프레임에 2018년 연봉 정보를 합칩니다.
result_df = picher_df.sort_values(by=['y'], ascending=False)
result_df.drop(['연봉(2017)'], axis=1, inplace=True, errors='ignore')
result_df = result_df.merge(picher, on=['선수명'], how='left')
result_df = result_df[['선수명', 'y', '예측연봉(2018)', '연봉(2017)']]
result_df.columns = ['선수명', '실제연봉(2018)', '예측연봉(2018)', '작년연봉(2017)']
# 재계약하여 연봉이 변화한 선수만을 대상으로 관찰합니다.
result_df = result_df[result_df['작년연봉(2017)'] != result_df['실제연봉(2018)']]
result_df = result_df.reset_index()
result_df = result_df.iloc[:10, :]
result_df.head(10)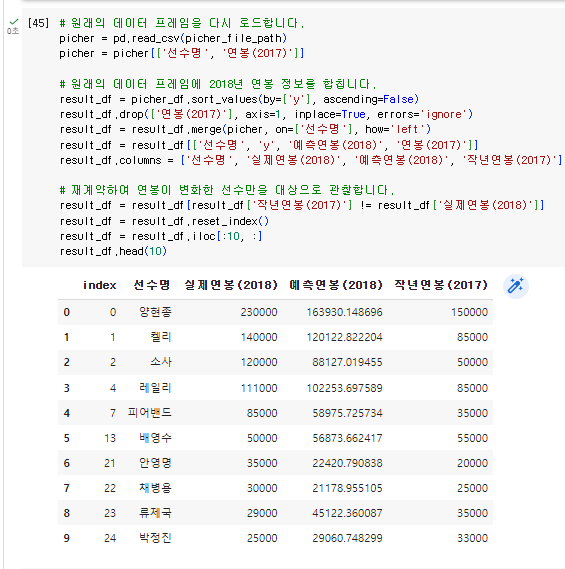
# 선수별 연봉 정보(작년 연봉, 예측 연봉, 실제 연봉)를 bar 그래프로 출력합니다.
mpl.rc('font', family='NanumGothic')
result_df.plot(x='선수명', y=['작년연봉(2017)', '예측연봉(2018)', '실제연봉(2018)'], kind="bar")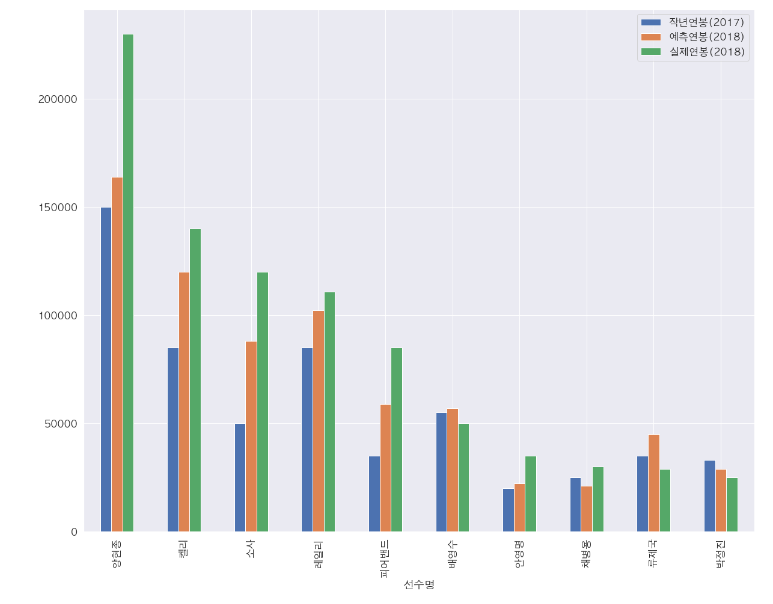
출처
아래 링크를 보고 학습했으니 필요하시다면 참고하세요!
■ https://seethefuture.tistory.com/57
728x90
반응형
'Language > Python' 카테고리의 다른 글
| [Python] 개인정보 마스킹 처리하기 (0) | 2023.12.12 |
|---|---|
| [Python] Faker를 사용해 가상의 개인정보 파일 제작하기 (0) | 2023.12.12 |
| [Python] selenium 라이브러리 사용하기 (0) | 2023.03.21 |
'Language/Python' Related Articles
more


